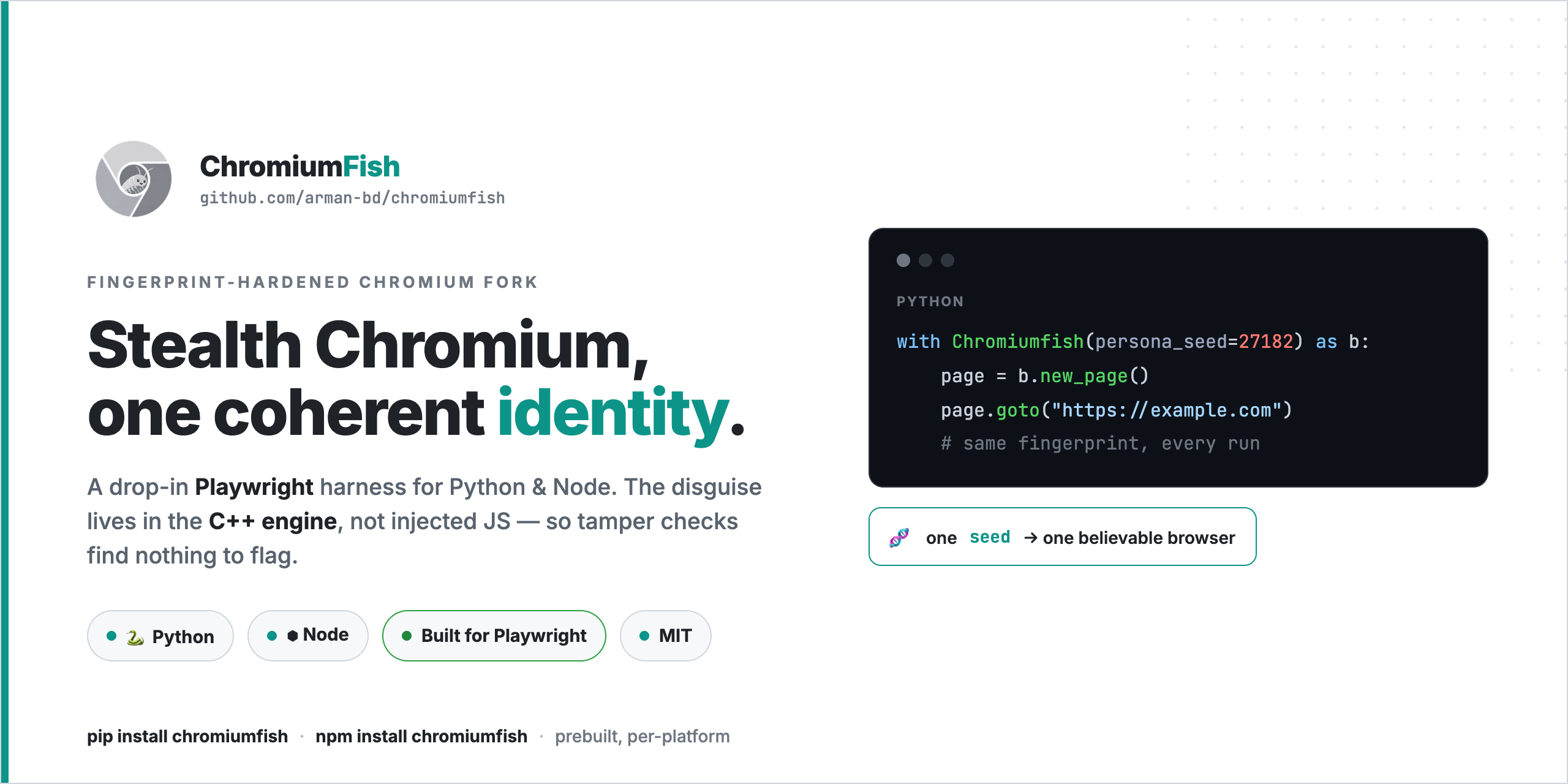
ChromiumFish: A Stealth Browser Built Where Detectors Can't Look
Every anti-bot fight eventually comes down to one question: at which layer are you fighting it? Spend enough time unblocking scrapers and you start to see that the answer decides everything. Pick t...